반응형
[본글은 고려대학교 정보대학 유용재 교수님 COSE 471 데이터과학 수강중 중간고사 정리를 위해 작성하는 글임을 밝힙니다.]
상관 계수와 상관분석의 기초
Pearson Correlation Coefficient
- 두 변수 사이에 존재하는 선형적인 상관관계를 수치로 나타낸 것
- 크기는 -1 에서 1 사이. 0일 경우 상관관계가 없음
주의 사항
- 선형적인 상관관계만을 드러낸다
- 큰 상관 계수가 인과관계를 보장하는 것은 아니다
- 상관 계수와 기울기를 혼동 해서는 안된다.
Spearman Correlation Coefficient
- 값이 아닌 순위 기반으로 상관계수를 도출함
Kendall tau Correlation Coefficient
- 값이 아닌 순위 기반으로 상관계수를 도출한다는 점은 동일함
- ((concordant 순서쌍) - (discordant 순서쌍)) / 전체 데이터가 가질 수 있는 순서쌍
- 순서쌍에서 두 변수간의 대소관계가 동일하면 concordant하다고 한다.
상관 계수와 상관분석의 기초
- 선형회귀의 목적: Mean Squared Error (평균 제곱오차)를 최소화 하는 것
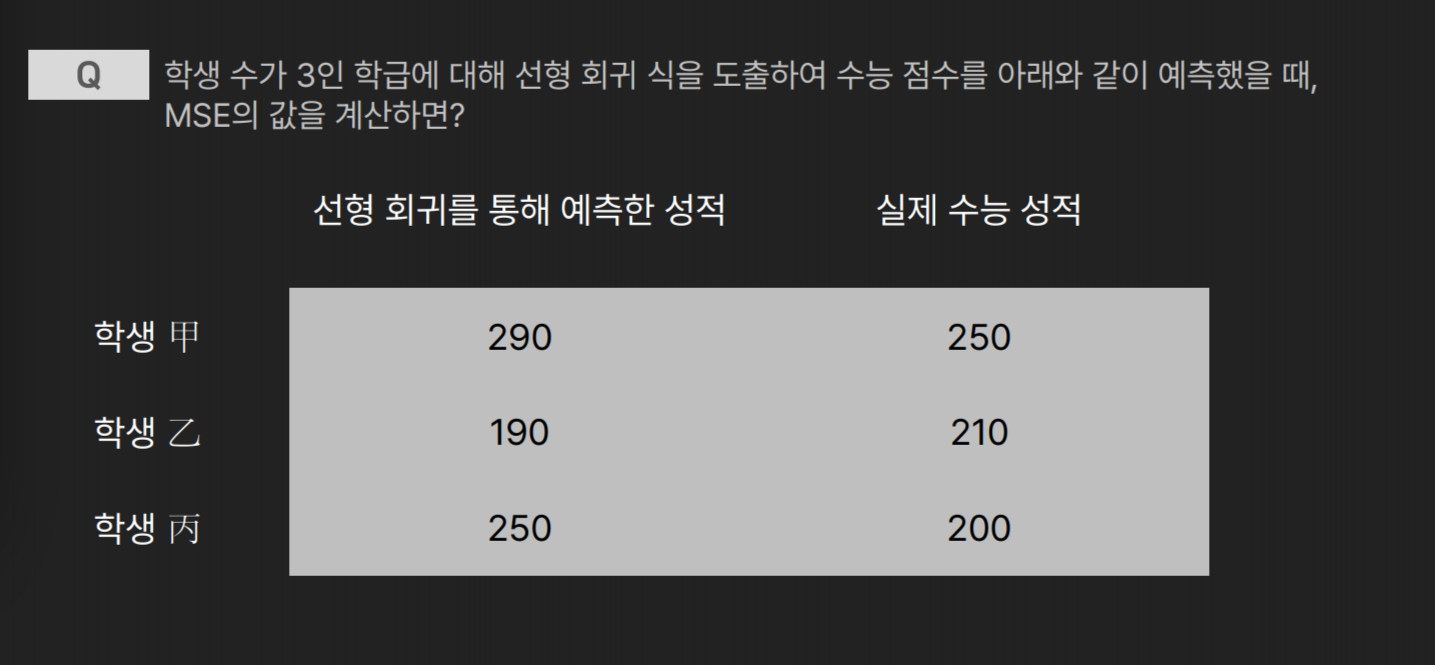
MSE: ((290-250)^2 + (190-210)^2 + (250 - 200)^2 )/3 =1500
선형회귀 구현을 위한 라이브러리
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split // training data, validation data로 나눠주는 라이브러리
from sklearn.linear_model import LinearRegression // 선형회귀를 위한 라이브러리
df= pd.read_csv('score.csv')
df_x=df[['1st','2nd','3rd','6mo','9mo']]
df_y=df['suneung']
x_train,x_valid,y_train,y_valid = train_test_split(df_x,df_y,random_state=0,test_size=0.2)
reg =LinearRegression()
reg.fit(x_train,y_train)
print(reg.coef_) // 계수 출력
print(reg.intercept_) // 절편 출력
y_pred=reg.predict(x_valid) // x_valid에 대한 예측 결과 값 계산K-Fold
- 데이터가 적을 때 사용 하는 방법으로 데이터를 K개로 나눈후, K-1개는 train data, 1개는 valid data로 실행을 한다.
반응형
'Data Science' 카테고리의 다른 글
| KNN,Naive Bayes, Laplacian Correction 연습 문제 모음 (1) | 2024.06.09 |
|---|---|
| 공공 데이터 품질 관리와 오류율 (0) | 2024.04.17 |
| OpenApi와 공공데이터에 대한 이해 (0) | 2024.04.17 |


